
Evaluating LLMs in cancer care: Why Sheets are all you need when getting started
Evaluating LLMs in cancer care: Why Sheets are all you need when getting started

In our previous post, we discussed the unique challenges involved in building a large language model (LLM) enabled product for healthcare. While LLMs offer significant potential, a considerable amount of work is required throughout the process to integrate them into a product in a way that aligns with the desired behavior. Critical requirements like accuracy, alignment, interpretability, and reproducibility present their own challenges, which must be carefully addressed to ensure the system is reliable and trustworthy. By honing in on the specific challenge of identifying workup gaps for patients recently diagnosed with breast cancer, we positioned ourselves to take a focused, methodical approach to these problems. Additionally, we highlighted the importance of curating patient cases and leveraging expert-generated workup plans as a baseline for evaluating and improving system performance—a crucial first step in driving meaningful improvements.
LLM System Optimization
The world of LLM system improvements & optimization is daunting, and there are a plethora of techniques and tools that purport to solve this problem. Additionally, the space is evolving rapidly. An appropriate solution architecture today may be overthrown by a new model release or publication tomorrow.
With these considerations in mind, we arrived at the following core tenants of our evaluation & experimentation system:
Put the system’s output at the forefront of evaluation. A quick Google search for How to Evaluate LLMs will yield an extraordinary catalog of metrics that aim to quantitatively capture LLM performance along different dimensions. Our stance was that numerical measures of performance should not disconnect us from the output that the user will see when they use the product. We need to be close to that data because a system that performs well is one that is optimized to perform well against the nuances of the task it is designed to solve, and while numerical measures are great indicators of performance, they can easily oversimplify or strip away the nuances of real-world interactions. By focusing solely on numbers, we risk losing sight of the user experience and the specific context the system is meant to handle. Ultimately, true performance is reflected in how well the system serves its intended purpose, not just in how it meets numerical targets.
Make it easy to assess numerical measures and update how they’re computed. The qualitative insights gained from close interaction with the data are invaluable, as they help us continuously refine our understanding of what it means for the system to be good. However, this qualitative approach encounters limitations at scale. As we expand our range of quality dimensions through qualitative evaluation, we need the ability to easily assess and update automated methods for capturing these dimensions numerically.
Be un-opinionated about the underlying system. We need to have the flexibility of easily making changes to or even overhauling how our system works under the hood.
The Tooling That Powers It
We sought to develop an evaluation and experimentation system that would enable us to meet the principles described above without slowing us down. While we evaluated some off-the-shelf solutions, we ultimately decided that, given the stage of development we were in, we needed tooling that would enable us to move incredibly quickly while also allowing us to fundamentally rework our approach as needed. At the same time, the system had to be rooted in end-to-end output analysis. With these goals in mind, we designed the following system—a platform where we could rapidly prototype different versions of our system, each representing an experiment, and share the outputs and performance of these experiments against our validation and test data (see our previous post for the definition of this), built on 2 tools:

Google Colab – a hosted Jupyter Notebook service offering free compute resources. We chose Colab for several reasons:
Quick to start – With just a Google account, anyone can create a Colab notebook, start prototyping, and share their work immediately. This allowed us to skip the overhead of setting up infrastructure or onboarding vendors.
Extremely flexible – Colab runs Python code directly in the cloud, and its un-opinionated design lets us architect our system in any way that suits our needs. We’re free to use any Python package or structure, offering full control over how we build.
Designed for collaboration – Early on, we prioritized making experimentation accessible across the team. Colab supports this by allowing anyone to easily explore and modify our system’s internals. With Colab Forms, even non-technical team members can adjust key parameters like the knowledge bases used, choice of LLM, or temperature settings, directly influencing system performance. Built on top of Jupyter Notebooks—a widely used tool for prototyping—Colab seamlessly integrates code with documentation, making the process both intuitive and easy to follow.
Seamless GSuite integration – Colab effortlessly connects with GSuite products like Google Sheets, making it easy to read and write data. This is especially beneficial in our cross-functional, collaborative work environment.
Quick to start – With just a Google account, anyone can create a Colab notebook, start prototyping, and share their work immediately. This allowed us to skip the overhead of setting up infrastructure or onboarding vendors.
Extremely flexible – Colab runs Python code directly in the cloud, and its un-opinionated design lets us architect our system in any way that suits our needs. We’re free to use any Python package or structure, offering full control over how we build.
Designed for collaboration – Early on, we prioritized making experimentation accessible across the team. Colab supports this by allowing anyone to easily explore and modify our system’s internals. With Colab Forms, even non-technical team members can adjust key parameters like the knowledge bases used, choice of LLM, or temperature settings, directly influencing system performance. Built on top of Jupyter Notebooks—a widely used tool for prototyping—Colab seamlessly integrates code with documentation, making the process both intuitive and easy to follow.
Seamless GSuite integration – Colab effortlessly connects with GSuite products like Google Sheets, making it easy to read and write data. This is especially beneficial in our cross-functional, collaborative work environment.
Google Sheets – a cloud-based spreadsheet application that enables real-time collaboration, data analysis, and automation through built-in formulas and integrations. We chose Google Sheets for interacting with the data produced by our Colab notebooks for many of the same reasons we chose Colab, though with slightly different applications:
Quick to start – Setting up a shared drive for storing all the data our system ingested and produced was quick and easy. This made the data readily accessible to our diverse team of medical professionals, product managers, designers, and engineers. Since we were already using GSuite as a company, collaboration in Google Sheets was effortless, enabling everyone to access and contribute effortlessly.
Extremely flexible – As we iterated on how we evaluated our system, Google Sheets provided the flexibility to quickly adapt the structure of our performance and evaluation data based on new learnings from each round of experimentation.
Designed for collaboration – A core principle for us was ensuring that everyone, with their wide range of expertise, could be actively involved in evaluating the system. Each team member brought a unique perspective, whether from medical, product, design, or engineering backgrounds, and it was crucial that we had an easy-to-use, collaborative platform where these diverse insights could be captured and translated into meaningful system improvements. Google Sheets gave us exactly that, offering a seamless way for all contributors to share their feedback and engage with others’ feedback in real time.
By leveraging Google Colab and Google Sheets, we quickly built a highly adaptable and collaborative experimentation and evaluation system aligned with our core tenets. Colab’s fast startup, unopinionated architecture, and seamless GSuite integration enabled rapid iteration, keeping our focus on real-world system performance rather than infrastructure. Meanwhile, Google Sheets offered the flexibility and accessibility needed for cross-functional collaboration, allowing diverse team members to shape and influence how we measured performance and improved the system. Together, these tools empowered us to stay agile, continuously improve, and strike a balance between qualitative insights and quantitative evaluation, ensuring the system was optimized for the specific challenge we set out to solve.
Tip: When leveraging LLMs to solve a problem, you don’t know what you don’t know in terms of how the system will behave and all the ways it may not align with your goal. Choose tooling that enables you to learn quickly, iterate, and build a system that addresses the problem it’s meant to solve without pigeonholing you into any particular solution architecture or evaluation methodology.
Our Optimization Workflow
The workflow built on top of these tools is illustrated in the graphic below. As outlined in our previous blog post, the starting point for evaluation and experimentation was curating the validation and test datasets. Once these datasets were available, we developed an experimentation template notebook in Colab. This template, which each new experiment would be forked from, contained the code for our best-performing experiment at that time, establishing a baseline for performance.
The goal of this approach was twofold: to minimize the overhead associated with initiating new experiments and sharing their results, and to ensure a consistent experimental methodology. Specifically, by keeping all variables between the baseline (the code in the template) and the experiment constant except for one, we could more confidently attribute any observed performance changes to the experimental variation, thereby enhancing the rigor of our evaluations.
Upon executing the experiment notebook, an analysis spreadsheet is automatically generated in Google Sheets. This spreadsheet compares the system’s outputs against the ground truth in our validation dataset for each patient case. The analysis then enters a collaborative review process involving team members, who critically evaluate the system’s performance. Based on these findings, two key outcomes emerge: the generation of hypotheses for subsequent experiments aimed at improving system performance, and the development of enhancements to the evaluation process itself.
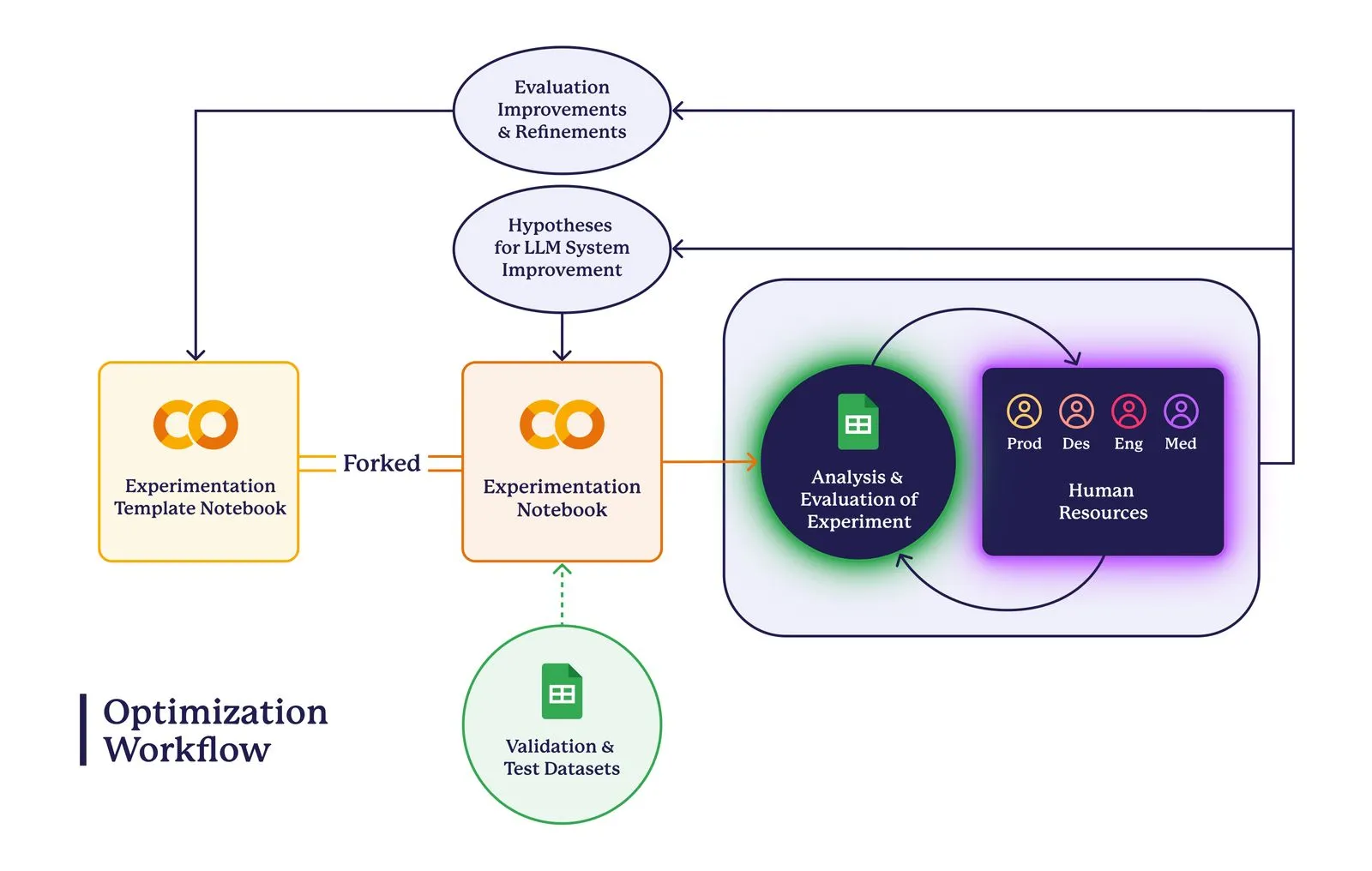
In conclusion, building with LLMs doesn’t have to be complicated or tied to heavyweight infrastructure from the start. By using Google Colab and Google Sheets, we created a flexible, collaborative system that enabled quick iterations and meaningful insights. This lightweight approach allowed us to stay focused on improving real-world performance while remaining adaptable to the evolving challenges of optimizing LLM-enabled systems.
Next Up
In our next post, we’ll explore the key metrics we use to assess system quality, followed by how our workflow has evolved to build trust in automated evaluation and streamline the manual review process.