Expert, clinical cancer care from anywhere.
For any type.
At any point.
At any stage.
For every person.
For every workforce.
For every member.
For every team.

Access. Speed. Direct clinical care.
For better outcomes and lower costs.

Expert, clinical cancer care from anywhere.
For any type.
At any point.
At any stage.
For every person.
For every workforce.
For every member.
For every team.







Cancer is changing, and organizations are now on the front line of one of the most complex and costly healthcare challenges. In this video, Color CEO Othman Laraki explains how Color’s Virtual Cancer Clinic delivers oncologist-led care across the cancer journey to improve outcomes, expand access, and reduce costs.

Where traditional programs fall short, Color delivers what is needed. By shifting focus to direct clinical care, employers can go beyond offering simple navigation to impact outcomes and costs. Color partners with local providers to clinically manage all patients through our oncologist-led care team that stays connected with your members from detection and diagnosis, to delivering ongoing Expert Medical Opinion and clinical oversight through treatment, survivorship, and supporting back to work.
Our Virtual Cancer Clinic is a national, virtual cancer center of excellence, built to expand access to oncology expertise at scale. Color is ASCO Certified by the American Society of Clinical Oncology, the leading professional organization for cancer physicians, meeting the same rigorous quality and safety standards as top cancer centers and independently validating a more accessible, AI and technology-enabled model of cancer care.
Explore the Virtual Cancer ClinicCancer is most treatable and least costly when caught early. Color identifies risk, gets people screened, and moves quickly on 100% of abnormal results to maximize care.

Treatment decisions are high stakes. Color’s oncologist-led clinical team reviews each diagnosis and treatment plan, works directly with treating providers, and manages symptoms to keep care on track.

Cancer care does not end with treatment. Color’s survivorship oncologists monitor recurrence risk, support long-term health, and help people return to health, life, and work.

Color is built to manage cancer as a clinical problem, not a collection of services. Our model focuses on three key levers that consistently drive better outcomes and lower costs.
Learn more about the Virtual Cancer ClinicNationwide care coverage
At-home cancer screening and testing
24/7 access to oncologist-led clinical care
A care team focused exclusively on cancer
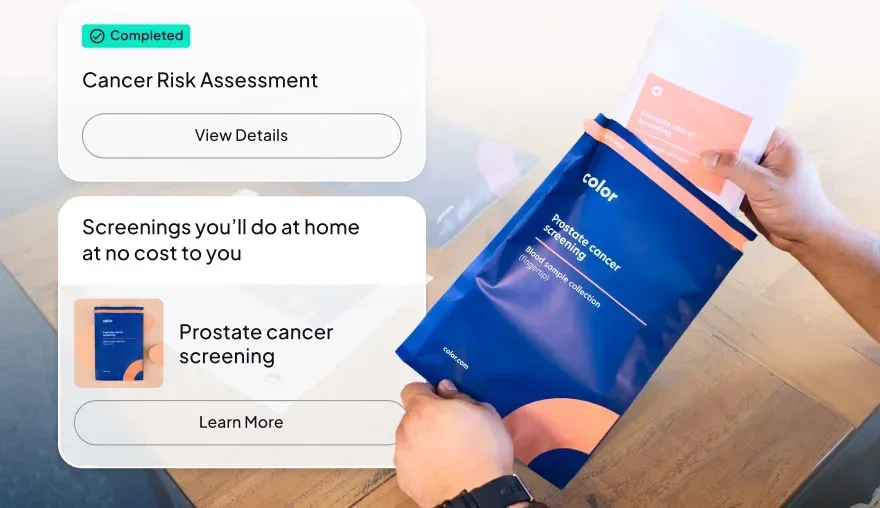
Earlier risk identification that triggers action
Higher screening completion, not just referrals
Fast clinical follow-up on abnormal results
Shorter time to confirmed diagnosis and treatment

Board-certified oncologists, not simple navigators
Licensed medical group across all 50 states
Active treatment, symptom management, and Expert Medical Opinion
Peer-to-peer collaboration with treating providers

faster diagnosis
increase in screening adherence
of costly care gaps closed
saved per patient in treatment
saved per survivor
in Year 1


Give your workforce real engagement, improved experience, and direct oncologist-led care.

Equip clients with measurable improvements in cost, experience, and outcomes.

Improve member outcomes with a cancer-specific clinical program that diagnoses earlier and prevents costly delays.

Support members and their families with fast, expert cancer care.

Bring accessible, expert cancer care to diverse and distributed communities.
“My Color clinician was kind, thorough, patient, explained everything well, and asked all the right questions. I felt heard, educated, and like there was someone in my corner making sure my concerns had a voice.”
Color Patient

Color Patient

“In my most overwhelming moment, Color made everything feel manageable. My oncologist truly listened, and they have supported me through every step of my diagnosis, treatment, and survivorship.”
Color Patient
